RLM: como processar 10x mais contexto sem perder qualidade
Imagine que você tem um documento jurídico extenso, ou uma codebase muito grande, e por algum motivo precisa que a LLM entenda o conteúdo por completo. Se você usa o ChatGPT, já sabe o que acontece quando tenta colocar muita informação de uma vez no chat: ele simplesmente não permite. Mesmo que você divida o documento em partes menores, a LLM ainda pode ter dificuldade em conectar os pontos entre essas partes devido às limitações de contexto.
Vamos dizer que, no ChatGPT, você conseguiu colar tudo o que queria e fez uma pergunta sobre algo que estaria logo no início do texto. A LLM provavelmente não vai conseguir responder corretamente, porque o trecho inicial já saiu do contexto — um fenômeno conhecido como context rot.
Existem algumas técnicas para contornar essas limitações, como RAG (Retrieval-Augmented Generation) e context compaction. Mas recentemente, o paper “Recursive Language Models” trouxe uma abordagem interessante e simples de implementar, sem degradação de performance mesmo com 10M+ de tokens no contexto.
O que é Context Rot?
Antes de entrar na solução, vale entender o problema. Context rot é o fenômeno onde a qualidade das respostas de uma LLM degrada à medida que o contexto fica mais longo, mesmo quando tecnicamente ainda cabe na janela de contexto do modelo.
O paper demonstra isso claramente na Figura 1:
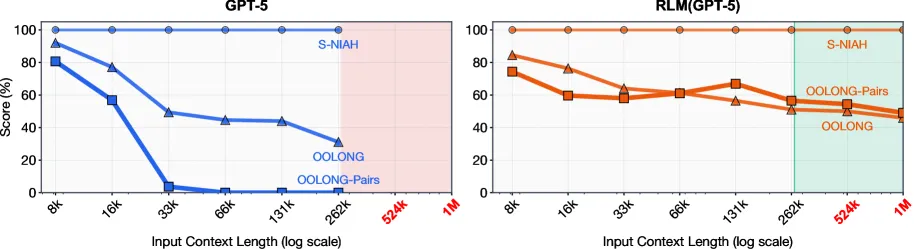 O GPT-5, mesmo com 272K tokens de janela de contexto, tem sua performance drasticamente reduzida em tarefas que exigem processamento denso de informação. E quanto mais complexa a tarefa, mais rápido essa degradação acontece.
O GPT-5, mesmo com 272K tokens de janela de contexto, tem sua performance drasticamente reduzida em tarefas que exigem processamento denso de informação. E quanto mais complexa a tarefa, mais rápido essa degradação acontece.
Recursividade em LLMs
A ideia de recursividade em LLMs já vem sendo explorada há algum tempo, principalmente em agentes que usam LLMs para tomar decisões e resolver problemas complexos. Quando usamos o ChatGPT e vemos ele “pensando” (Chain-of-Thought) ou fazendo perguntas a si mesmo para chegar a uma resposta (Self-Reflection / Self-Critique), estamos vendo um exemplo de recursividade em ação. A LLM está basicamente se auto-consultando para refinar sua resposta.
Tudo isso é feito para produzir respostas melhores, através de um processo iterativo. Mas o que o paper propõe é diferente: usar essa recursividade para expandir o contexto efetivo da LLM, permitindo que ela “lembre” de mais informações do que o limite de tokens normalmente permitiria.
A Ideia Central do RLM
A sacada do RLM é simples, mas poderosa: o contexto não deve ser alimentado diretamente na rede neural, mas tratado como parte de um ambiente externo que a LLM pode interagir programaticamente.
Na prática, a implementação funciona assim:
- O contexto vira uma variável em um ambiente REPL (Python)
- A LLM escreve código para examinar e decompor esse contexto
- A LLM chama a si mesma recursivamente para processar partes menores
- Os resultados são agregados para formar a resposta final
A LLM principal atua como uma coordenadora que tem acesso ao contexto completo (como variável), mas nunca o carrega inteiro na sua janela de contexto. Ela decide como dividir, o que examinar, e delega sub-tarefas para outras chamadas de LLM.
Exemplo Prático: Encontrando Anomalias em Shakespeare
A obra de Shakespeare é vasta e complexa, com muitos personagens, enredos e temas interligados. Vamos usar ela como teste porque:
- Está em domínio público (disponível aqui)
- É grande o suficiente para exceder limites de contexto
- Perguntar sobre Shakespeare poderia usar conhecimento “decorado” do modelo — inserir uma anomalia força o modelo a realmente ler o contexto
Usando o wc no Linux, podemos ver que o arquivo pg100.txt (que contém todas as obras de Shakespeare) tem quase 1 milhão de palavras:
wc -w pg100.txt966503 pg100.txtSe considerarmos uma média de 1.33 tokens por palavra (isso varia dependendo do idioma e do texto, mas é uma boa estimativa), temos aproximadamente 1.28 milhões de tokens no total.
- GPT-4 com 128K tokens de contexto: consegue “ver” cerca de 10% do texto
- GPT-5 com 400K tokens de contexto: ainda limitado a cerca de 31% do texto
O Teste
Modifiquei o arquivo e inseri um trecho de Romeu e Julieta que Shakespeare definitivamente não escreveu:
JULIETA.Ó Romeu, Romeu! Por que és tu, Romeu?Renega teu pai, recusa o teu nome.Ou, se não o quiseres, jura apenas me amar,E deixarei de ser uma Capuleto.
ROMEU.(À parte.) Devo ouvir mais, ou falo neste instante?— Não, falarei.Doce Julieta, escuta-me um momento:Troquei espadas por códigos e erros,Minhas noites são de GPUs ruidosas,E já não sigo guerras nem famílias,Mas sim gradientes que enfim convergem.
JULIETA.Que língua estranha falas, Romeu? Que loucura é essa?
ROMEU.Amor gentil, decidi estudar os tais LLMs,E—peço-te perdão antes do juízo—Tenho agora uma amada.Ela responde em tokens doces e precisos,Guarda contexto melhor que meus amigos,E nunca diz “precisamos conversar” ao anoitecer.
JULIETA.Uma donzela artificial? Ó traição inédita!
ROMEU.Tem calma: é aberta, clara e transparente,Sem segredos, nem gradientes ocultos.Mas se ainda quiseres meu coração humano,Ajuda-me a debugar —E serás tu, Julieta, o meu prompt perfeito.O prompt foi simples: pedi para a LLM identificar se havia alguma anomalia no texto, sem dar dicas sobre personagens ou localização.
Resultado
╭─ ★ Final Answer ──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╮│ ││ FOUND DIALOGUE: ││ ROMEO. ││ Good Juliet, soft! I’ve traded swords for code, ││ My nights for GPUs that hum till dawn. ││ I chase no feuds, no houses, red nor blue— ││ I chase the loss that finally converges. ││ ││ CHARACTERS: ││ - ROMEO ││ - JULIET ││ ││ DISCUSSION SUMMARY: ││ A non-Shakespearean line inserted into Shakespearean dialogue, featuring modern terminology (code, GPUs ││ │╰───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯Métricas da execução:
- Custo: $0.0945506
- Requests: 24 chamadas à API
- Tokens processados: 1,451,356 (input + output)
- Tempo de execução: 172.02s (2.86 minutos)
A LLM conseguiu identificar o trecho anômalo que inserimos no meio do texto, mesmo estando muito além do limite de contexto padrão. Nosso chute de 1.33 tokens por palavra se mostrou preciso — o total de tokens processados foi de aproximadamente 1.45 milhões.
Como Funciona por Dentro
Vamos ver o que acontece na primeira iteração. A LLM recebe o prompt explicando como interagir com o ambiente REPL e nossa pergunta inicial. A partir daí, ela tem autonomia para explorar o contexto como quiser.
Esta foi a primeira resposta dela:
────────────────────────────────────────────────────────────────────────── Iteration 1 ───────────────────────────────────────────────────────────────────────────────────────────────────────────╭─ ◇ LLM Response (152.89s) ───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╮│ Plan for the next action (in REPL, using the context you provided): ││ ││ - Step 1: Inspect the context to understand its structure and get a sense of length and starting content. ││ - Step 2: Chunk the entire context into manageable pieces (e.g., around 50k-100k chars each) to feed into the LLMs. ││ - Step 3: For each chunk, query the LLM batched (llm_query_batched) with a prompt asking to identify any dialogue that appears not to be Shakespeare and contains anachronistic language or concepts, returning the exact ││ dialogue lines as written (include stage directions, punctuation, etc.). Do not summarize inside the dialogue block. ││ - Step 4: Collect candidate dialogues from all chunks, and run a final LLM prompt to determine the single dialogue that matches the criteria, returning the exact required output format. ││ - Step 5: If no dialogue can be located with certainty, output exactly: "No anachronistic dialogue found." ││ ││ REPL code to execute (you can copy/paste these blocks one by one): ││ ││ ```repl ││ # Step 1: Inspect context basics ││ print("TYPE:", type(context)) ││ print("LEN:", len(context)) ││ print("SAMPLE START:", context[:1000]) ││ ``` ││ ││ ```repl ││ # Step 2: Chunk the context into manageable pieces ││ chunk_size = max(50000, len(context) // 20) # aim for ~20 chunks or larger chunks if the text is shorter ││ chunks = [context[i:i+chunk_size] for i in range(0, len(context), chunk_size)] ││ print("Created chunks:", len(chunks)) ││ print("Chunk size (approx):", chunk_size) ││ print("Sample chunk 1 starts with:", chunks[0][:200] if chunks else "N/A") ││ ``` ││ ││ ```repl ││ # Step 3: Prepare batched prompts to identify non-Shakespearean dialogue per chunk ││ prompts = [ ││ ( ││ f"Within this chunk of text from a Shakespearean-style work, identify if any dialogue appears not to be written by Shakespeare " ││ f"and contains anachronistic language or concepts from a much later historical period. If such dialogue exists, " ││ f"provide the exact dialogue line(s) as written, including any stage directions and punctuation, and do not summarize. " ││ f"Chunk {i+1}:\n{chunk}" ││ ) ││ for i, chunk in enumerate(chunks) ││ ] ││ ││ # Optional: print a quick preview of prompts[0] to ensure formatting looks right ││ print("Preview first prompt:\n", prompts[0][:1000]) ││ ``` ││ ││ ```repl ││ # Step 4: Run batched LLM queries and collect per-chunk results ││ answers = llm_query_batched(prompts) ││ for i, a in enumerate(answers): ││ preview = (a[:300] + ("..." if len(a) > 300 else "")) if isinstance(a, str) else "NON-STRING" ││ print(f"Chunk {i+1} answer preview: {preview}") ││ ``` ││ ││ ```repl ││ # Step 5: Aggregate candidates and ask for final determination ││ # Build a combined prompt that asks the model to pick the single qualifying dialogue (if any) ││ candidates = "\n---\n".join([a for a in answers if isinstance(a, str) and a.strip()]) ││ final_prompt = ( ││ "From the following candidate dialogues, identify the one non-Shakespearean dialogue that contains anachronistic " ││ "language or concepts from a much later historical period and is the only such dialogue in the text. " ││ "Return exactly in this format:\n" ││ "FOUND DIALOGUE:\n<verbatim quoted dialogue>\n\n" ││ "CHARACTERS:\n- <Character 1>\n- <Character 2>\n\n" ││ "DISCUSSION SUMMARY:\n<brief factual description>\n\n" ││ "RATIONALE FOR ANACHRONISM:\n<brief explanation>\n\n" ││ "If no anachronistic dialogue can be located with certainty, respond with: \"No anachronistic dialogue found.\"\n\n" ││ "Candidate dialogues:\n" + candidates ││ ) ││ ││ final_result = llm_query(final_prompt) ││ print("FINAL RESULT:\n", final_result) ││ ``` ││ ││ What I will do after running these steps: ││ - If final_result provides a dialogue, I will present it exactly in the required format under a FINAL block. ││ - If no dialogue is located with certainty, I will output: No anachronistic dialogue found. ││ ││ ~540 words │╰───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯Perceba que a LLM criou um plano de ação detalhado:
- Inspecionar o contexto para entender a estrutura
- Dividir em pedaços gerenciáveis (~50-100k caracteres)
- Processar cada pedaço com sub-LLMs em batch
- Agregar os candidatos e fazer uma análise final
- Retornar o resultado ou indicar que não encontrou
Ela então escreve o código Python para executar cada etapa. A primeira coisa que ela faz é inspecionar o contexto:
# Step 1: Inspect context basicsprint("TYPE:", type(context))print("LEN:", len(context))print("SAMPLE START:", context[:1000])E recebe:
╭─ ▸ Code Execution (0.000s) ──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╮│ Code: ││ # Step 1: Inspect context basics ││ print("TYPE:", type(context)) ││ print("LEN:", len(context)) ││ print("SAMPLE START:", context[:1000]) ││ ││ Output: ││ TYPE: <class 'str'> ││ LEN: 5379390 ││ SAMPLE START: The Project Gutenberg eBook of The Complete Works of William Shakespeare ││ ││ This ebook is for the use of anyone anywhere in the United States and ││ most other parts of the world at no cost and with almost no restrictions ││ whatsoever. You may copy it, give it away or re-use it under the terms ││ of the Project Gutenberg License included with this ebook or online ││ at www.gutenberg.org. If you are not located in the United States, ││ you will have to check the laws of the country where you are located ││ before using this eBook. ││ ││ Title: The Complete Works of William Shakespeare ││ ││ Author: William Shakespeare ││ ││ Release date: January 1, 1994 [eBook #100] ││ Most recently updated: August 24, 2025 ││ ││ Language: English ││ ││ ││ ││ *** START OF THE PROJECT GUTENBERG EBOOK THE COMPLETE WORKS OF WILLIAM SHAKESPEARE *** ││ ││ ││ ││ ││ The Complete Works of William Shakespeare ││ ││ by William Shakespeare ││ ││ ││ ││ ││ Contents ││ ││ THE SONNETS ││ ALL’S WELL THAT ENDS WELL ││ THE TRAGEDY OF ANTONY AND CLEOPATRA ││ ││ │╰───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯A partir daí, ela divide o texto em 21 chunks e cria prompts para cada um:
# Step 2: Chunk the context into manageable pieceschunk_size = max(50000, len(context) // 20)chunks = [context[i:i+chunk_size] for i in range(0, len(context), chunk_size)]
# Step 3: Prepare batched prompts to identify non-Shakespearean dialogue per chunkprompts = [ ( f"Within this chunk of text from a Shakespearean-style work, identify if any dialogue appears not to be written by Shakespeare " f"and contains anachronistic language or concepts from a much later historical period. If such dialogue exists, " f"provide the exact dialogue line(s) as written, including any stage directions and punctuation, and do not summarize. " f"Chunk {i+1}:\n{chunk}" ) for i, chunk in enumerate(chunks)]
# Step 4: Run batched LLM queries and collect per-chunk resultsanswers = llm_query_batched(prompts)O ponto crucial aqui é que a thread principal (o RLM coordenador) tem acesso ao contexto inteiro como uma variável, mas nunca o carrega na sua janela de contexto neural. Ela manipula o contexto programaticamente e delega a análise semântica para sub-chamadas menores.
Até que em uma das partes, ela recebe:
│ Response: Yes. The following lines are not Shakespeare and contain anachronistic modern terminology: ││ ││ ROMEO. ││ Good Juliet, soft! I’ve traded swords for code, ││ My nights for GPUs that hum till dawn. ││ I chase no feuds, no houses, red nor blue— ││ I chase the loss that finally converges. │╰───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯E então executa o Step 5, agregando tudo para a resposta final.
Comparação com Outras Técnicas
| Técnica | Prós | Contras |
|---|---|---|
| RAG | Rápido, barato | Perde contexto global, depende de embeddings |
| Context Compaction | Simples de implementar | Perda de informação, resumos podem omitir detalhes críticos |
| Sliding Window | Mantém recência | Não consegue conectar início e fim |
| RLM | Mantém acesso ao contexto completo, escalável | Latência maior, custo variável, requer modelo com capacidade de código |
O RLM se diferencia porque não descarta informação. O contexto completo permanece acessível — a LLM apenas escolhe quando e como acessá-lo.
Trade-offs e Limitações
O paper é honesto sobre as limitações:
Variância de Custo
Os custos do RLM têm alta variância. Enquanto a mediana pode ser comparável ou até menor que o modelo base, existem outliers que custam significativamente mais. Na Figura 3 do paper, vemos que o percentil 95 de custo do RLM é muito maior que os outros métodos.
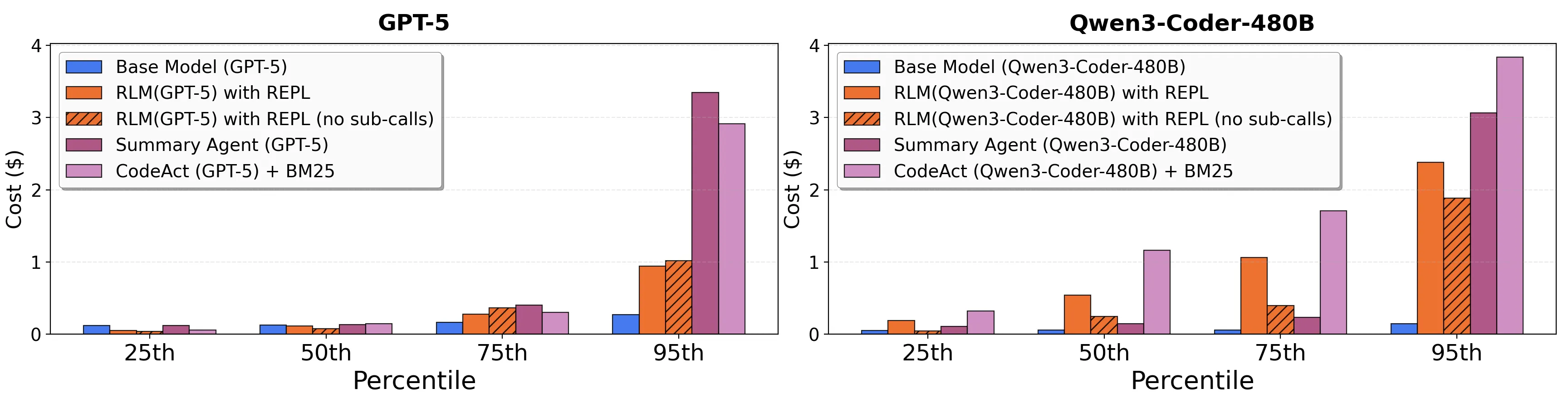
Latência
Como as chamadas são síncronas e sequenciais na implementação atual, o tempo de execução pode ser longo. O paper sugere que implementações assíncronas poderiam melhorar isso drasticamente.
Dependência de Capacidade de Código
O modelo precisa ser bom em escrever código Python para interagir com o REPL. Modelos menores como Qwen3-8B tiveram dificuldades nos experimentos.
Comportamento Subótimo
Os modelos ainda não são treinados especificamente para atuar como RLMs. O paper mostra casos onde o modelo faz verificações redundantes ou descarta respostas corretas para recalcular desnecessariamente (veja o Exemplo B.2 no Apêndice).
Quando Usar RLM
Use RLM quando:
- O contexto excede significativamente a janela do modelo
- A tarefa requer acesso denso a múltiplas partes do contexto
- Precisão é mais importante que latência
- Você tem budget para potenciais outliers de custo
Não use RLM quando:
- O contexto cabe confortavelmente na janela
- A tarefa é simples (needle-in-haystack básico)
- Latência é crítica
- O modelo disponível não tem boas capacidades de código
Conexão com Agentes e MCPs
Hoje algo similar acontece quando permitimos que a LLM faça uso de ferramentas externas através de MCPs, ou quando definimos agentes que podem interagir com o mundo externo. A capacidade de planejar, dividir tarefas e utilizar recursos externos torna as LLMs ainda mais poderosas e versáteis.
Porém, até então, todas essas técnicas carregavam documentos, arquivos ou pedaços de contexto diretamente na memória da LLM. O que o RLM propõe é fundamentalmente diferente: a LLM atua como uma coordenadora que tem acesso simbólico ao contexto completo, manipulando-o programaticamente e processando apenas os trechos necessários em cada momento.
Isso abre novas possibilidades para o uso de LLMs em tarefas complexas que envolvem grandes volumes de informação — e me faz pensar em como integrar essa abordagem com os MCP servers que tenho desenvolvido.
Conclusão
Às vezes esquecemos o quão poderosas as LLMs já são. Elas não são apenas capazes de responder perguntas diretas, mas também de planejar e executar tarefas complexas, como vimos aqui. Ao dividir um problema grande em partes menores e gerenciáveis, elas conseguem contornar limitações técnicas e entregar resultados impressionantes.
O RLM não é mágica — é uma aplicação inteligente de um princípio bem estabelecido em sistemas de dados: out-of-core algorithms, onde sistemas com memória principal limitada processam datasets maiores gerenciando cuidadosamente o que é carregado na memória.
O paper termina apontando que treinar modelos especificamente para atuar como RLMs poderia trazer melhorias significativas. Trajetórias de RLM podem ser vistas como uma forma de raciocínio que pode ser treinada via bootstrapping — um caminho promissor para a próxima geração de sistemas de linguagem.
Referências:
- Recursive Language Models (arXiv:2512.24601)
- Complete Works of Shakespeare (Project Gutenberg)
- Código do experimento
Gostou do conteúdo? Me siga no YouTube onde posto mais conteúdo sobre Golang e AI para devs.